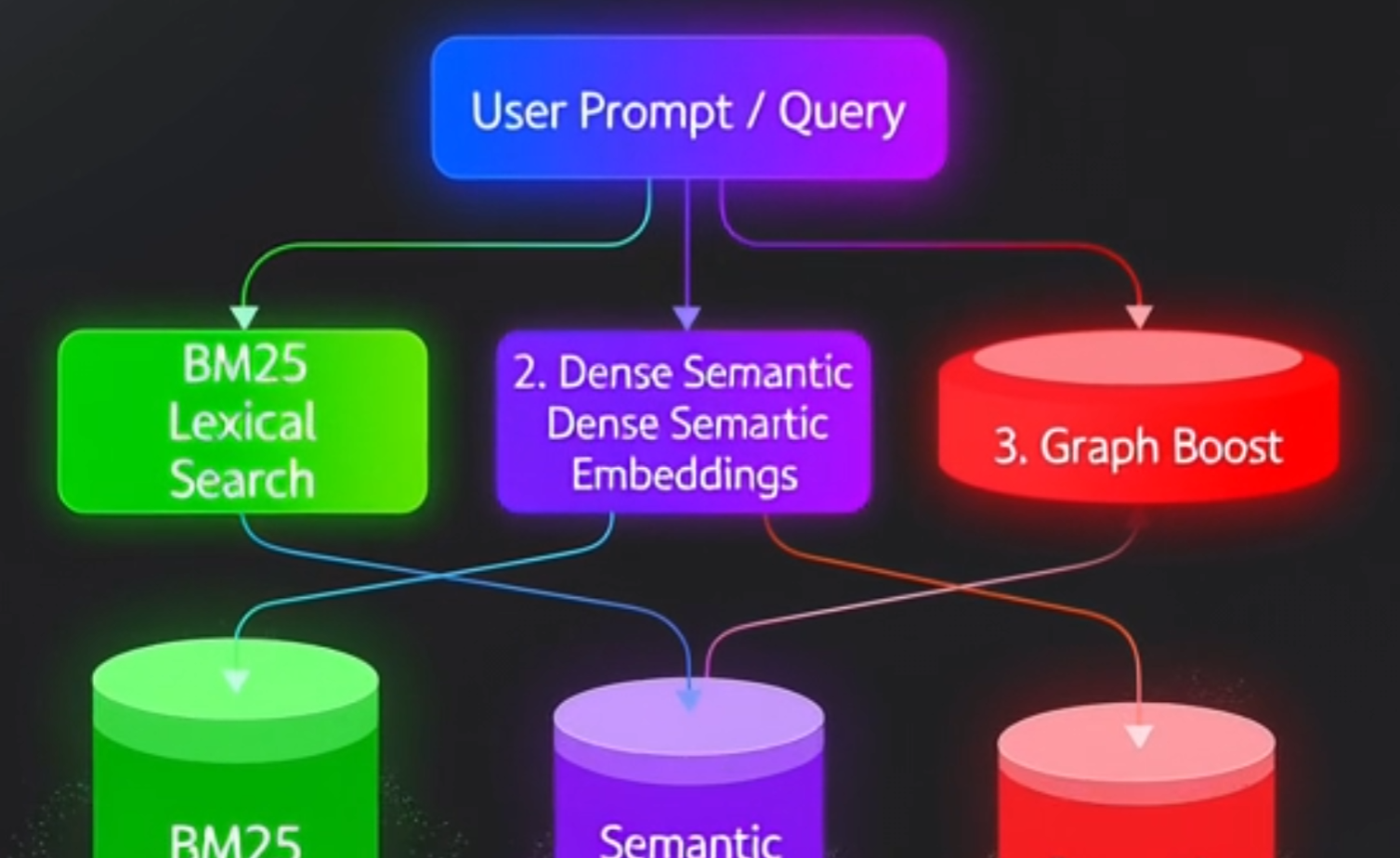
Lume is a Rust hybrid search engine that Steve Harris and I have been building in the open at github.com/DeepBlueDynamics/lume. It’s a small CLI plus an MCP server, BSD-3 licensed, and built around a stubborn idea: when an agent asks a question, every step from query to evidence should be inspectable.
Lume indexes Markdown, source code, and PDFs (via a small Python extractor) and ranks over them with three independent primitives — field-aware BM25, dense GTR-T5 vectors via Shivvr, and a significance-scored entity graph. The lexical core and the graph run entirely on your machine; only the dense vectors call out, and that endpoint defaults to localhost. There is no opaque “search box that returns a ranking” — every score has a name, a file, and a knob.
This post walks Lume’s retrieval core end to end, with line-level references to the current tree. If you’re building agentic systems and tired of treating retrieval as a magic step, this is for you.
A few principles up front, because they explain the design:
- Local-first. Lexical search and the entity graph run entirely on your machine. Dense vectors are fetched from Shivvr through
SHIVVR_BASE_URL, which defaults to a local endpoint. - Layered, not monolithic. BM25, semantic, and graph are independent signals with their own scores. The blend is one line; each input is replaceable.
- Auditable. The engine prints what it pruned, what it ranked, and why it rejected the rest.
0. The unit of retrieval: a Section
Lume indexes Markdown, cut into sections at # headers (parse_markdown in src/bm25.rs:211). A Section (src/bm25.rs:106) is the atom everything ranks over:
pub struct Section {
pub title: String,
pub body: String,
pub line_number: usize,
pub filename: Option<String>,
pub entities: Vec<String>, // resolved named entities, for the graph
}Title and body are separate fields with separate statistics — that distinction shows up immediately in scoring. The whole index lives in memory as a Bm25Index (src/bm25.rs:147): per-field term-frequency maps, document frequencies, field lengths, roaring-bitmap posting lists, prime/Gödel signature filters, and the entity posting lists that feed the graph.
1. Primitive: field-aware BM25
The lexical core is a field-aware BM25 with three selectable variants. The tuning defaults (Bm25Params in src/bm25.rs:125) are deliberately classic:
Self { k1: 1.2, b: 0.75, delta: 1.0, title_weight: 2.0, body_weight: 1.0 }k1 controls term-frequency saturation; b controls length normalization. The one opinionated choice is title_weight: 2.0: a title hit contributes twice as much as a body hit before the coordination factor is applied. That is useful, but it can overweight chapter titles when a query token is broad. Treat it as a knob, not a law.
IDF is the standard smoothed form, floored at zero, and each term’s contribution is computed per field then summed with the field weights (calculate_bm25_term_score in src/bm25.rs:728):
let len_normalization = 1.0 - b + b * (doc_len / avgdl);
match variant {
SearchVariant::Classic => idf * (tf * (k1 + 1.0)) / (tf + k1 * len_normalization),
SearchVariant::Plus => idf * ((tf*(k1+1.0))/(tf + k1*len_normalization) + params.delta),
SearchVariant::L => { let s = tf / len_normalization;
idf * (s*(k1+1.0))/(s + k1) },
}
// total_score += title_weight * title_score + body_weight * body_score; (src/bm25.rs:635)- Classic is textbook BM25.
- Plus adds a
deltafloor so a matched term never contributes nothing, countering BM25’s over-penalty of long documents. - L moves length normalization inside the saturation, smoothing very long docs.
Lume runs Classic by default (src/main.rs:1430).
2. Two-stage pruning: roaring union, then Gödel signatures
You don’t want to BM25-score all 1,926 sections of a book for every query. Lume’s search (src/bm25.rs:445) is two-stage.
Stage 1 — candidate gather. Union the roaring-bitmap posting lists of the query terms. This is a handful of bitset ORs and instantly narrows the corpus to sections that contain any query term:
// src/bm25.rs:460
let mut candidate_set = MiniRoaring::new();
let mut first = true;
for q_tok in &query_tokens {
if let Some(list) = self.posting_lists.get(&q_tok.bytes) {
if first {
candidate_set = list.clone();
first = false;
} else {
candidate_set = candidate_set.union(list);
}
}
}Stage 1b — Gödel tag-signature pruning. If the query tagger recognizes entities, each candidate section is verified against a prime-factored signature filter (PrimeFilter::test_tag_prime in src/fast_retrieval.rs:449, evaluated in src/bm25.rs:538). Each known tag output maps to a prime; a section’s tag signature is the product of its tag primes, so inclusion is checked by divisibility. Unknown query tags deliberately receive a dummy prime and fail closed. Candidates that fail are dropped as TagSignatureMismatch before heavier scoring.
Stage 2 — heavy scoring runs only on survivors. And the engine tells you the shape of the funnel on stderr (src/bm25.rs:557):
[Two-Stage Pruning] Pruned candidate space from 1926 to 302 (roaring generated: 609) sections in 54.70µs
Candidates: 609
Ranked: 302
Rejected:
TagSignatureMismatch: 307
...That accounting is not decoration — it’s the first thing you read when a query returns the wrong thing.
3. Query hygiene: stopwords and coordination
Two small primitives have outsized effects on quality.
Query-side stopword filtering (filter_query_stopwords in src/bm25.rs:98). Function and question words are stripped from the query only, never the index. Without it, “how does Dantès know Mercédès” is dominated by how/does/know, which match unrelated sections (a chapter literally titled “How a Gardener…”). The safety net: if every token is a stopword (“how are you”), the originals are kept so you still get results.
The coordination factor (src/bm25.rs:638). A document matching more of the distinct query terms should beat one that repeats a single common term. Lume multiplies the score by a coverage-based factor:
let coverage = matched_terms.len() as f64 / num_distinct as f64;
let coord = COORD_FLOOR + (1.0 - COORD_FLOOR) * coverage; // COORD_FLOOR = 0.5
total_score *= coord;So a section matching all three query terms keeps 100% of its score; one matching a single term out of three keeps ~⅔. For single-term queries coverage == 1.0, so ordinary lookups are untouched. It’s a gentle nudge, not a hard AND.
4. Primitive: dense vectors (local GTR-T5)
Lexical search can’t bridge a vocabulary gap — “starved to death” vs “gastroenteritis.” That’s the semantic primitive’s job.
Lume embeds text to 768-dimensional GTR-T5 vectors via Shivvr. The default base URL is http://localhost:8085 (src/hybrid.rs:777), and the request still requires a service token (src/hybrid.rs:784). There’s no dedicated embed endpoint, so embed_text (src/hybrid.rs:43) ingests into a throwaway scratch store and reads the vector straight off the response:
// 768-d GTR-T5 ("organize") vector, asserted on the way out:
if emb.len() != 768 { return Err(format!("Expected 768-d GTR-T5 vector, got {}", emb.len())); }At index time, sections are pushed into a semantic session (ensure_semantic_session in src/hybrid.rs:581). The clever part is incrementality: each section gets a content hash (section_hash in src/hybrid.rs:407) used as the remote chunk id, with line numbers deliberately excluded — so moving a section doesn’t force a re-embed. Re-indexing diffs by hash and tops up only what changed; a matching corpus fingerprint is a no-op. Query results are cached too (.lume-semantic-cache.json).
At query time, query_semantic_search (src/hybrid.rs:637) asks Shivvr for n=60 neighbors. If the index was built without semantic vectors, or the token is missing, search degrades cleanly to lexical BM25 and says so: an alpha > 0 request against a lexical-only index is told it got lexical-only (src/main.rs:1389).
5. Primitive: the Semantic Knowledge Graph (significance, not co-counts)
The third signal is structural. Lume builds an entity co-occurrence graph from pairwise roaring-bitset intersections — “counting the counts of things” (src/graph_search.rs:1). On its own that’s a write-only export; graph_search turns it into a query-time ranking signal, fully local.
The subtle, important bit is how edges are weighted. Raw co-occurrence and even Jaccard reward promiscuous hubs — an entity that appears everywhere co-occurs with everything. Lume defaults to a significance score instead (cooccurrence_relatedness in src/semantic_mesh.rs:558): of n docs, A appears in a, B in b, both in k; compare observed k against the independence expectation E = a·b/n as a z-score, log-compress it to preserve dynamic range, then squash with tanh:
let expected = a * b / n;
let variance = expected * (1.0 - a/n) * (1.0 - b/n);
let z = (k - expected) / variance.sqrt();
let compressed = z.signum() * (1.0 + z.abs()).ln(); // keep z=10 vs z=100 distinct
(compressed / 3.0).tanh() // -> [-1, 1]; negative = avoidanceThe result lives in [-1, 1]: positive for real association, negative for avoidance (entities that co-occur below chance). This is Trey Grainger’s foreground-vs-background SKG relatedness, reduced to the pairwise case. A regression test pins the behavior: a true pairing (edmond–dantès) outranks a promiscuous hub even when the hub has perfect Jaccard overlap (src/graph_search.rs:305). You can still pick legacy Jaccard with --scoring jaccard; the edge weight() (src/semantic_mesh.rs:532) selects, and clamps negative significance to 0 so avoidance never boosts.
The walk itself (compute_skg_scores in src/graph_search.rs:154):
- Resolve the query’s entities by sliding n-grams longest-first (so “edmond dantes” matches the stored “edmond dantès”),
max_ngram = 4. - Seed them at weight
1.0; walk one hop to the top-k(8) strongest neighbors, each carryingdecay * weight(decay = 0.5), taking the max across seeds — so a shared hub neighbor can’t be summed into dominance. - Accumulate per-section mass from the entity posting lists and normalize to
[0, 1].
6. The blend: one multiplicative line
Three signals — lexical, semantic, graph — fuse in blend_hybrid_scores (src/hybrid.rs:673). The default is multiplicative, so the lexical match leads and the other two lift it:
hybrid = bm25 * (1.0 + alpha * semantic + beta * skg);This keeps strong lexical hits on top while letting semantic and graph signals lift them. Recall expansion comes from two paths: semantic-only hits are admitted with bm25_score = 0, and SKG-only sections are admitted only when their normalized graph mass reaches SKG_EXPAND_MIN = 0.5 (src/graph_search.rs:22). In the lexical-only path those SKG-only sections are scored beta*skg, below comparable lexical matches (apply_skg_boost in src/graph_search.rs:218). Set beta = 0 and the graph term is removed.
There’s an alternate mode for when you want semantic/graph to be able to overtake lexical, gated behind LUME_BLEND_NORM=1, which puts all three on a comparable [0,1] scale (src/hybrid.rs:745):
// src/hybrid.rs:745
let hybrid_score = if normalize {
(bm25_score / bm25_max) + alpha * sem_score + beta * skg_score
} else if bm25_score > 0.0 {
bm25_score * (1.0 + alpha * sem_score + beta * skg_score)
} else {
sem_score + beta * skg_score // fallback for semantic-only recall expansion
};7. The tuning surface: what each knob actually does
Everything above is exposed on lume search (handle_search in src/main.rs:1295). Here’s the practical guide:
| Knob | Flag / env | Default | What it changes |
|---|---|---|---|
| Lexical ↔ semantic | -a, --alpha / ALPHA |
0.5 in lume search |
0.0 = pure BM25; higher values increase the GTR-T5 term. Raise it when the answer uses different words than the query. |
| Graph boost | -g, --graph / GRAPH_ALPHA |
0.4 |
Weight of the SKG term. Raise to pull in entity-related sections; 0 disables the graph (pure lexical+semantic). |
| Edge scoring | --scoring |
relatedness |
relatedness (significance, hub-resistant) vs jaccard (raw overlap). Use significance unless you’re reproducing old numbers. |
| Spell correction | -c, --spell-check |
off | Corrects each query word against the index vocabulary (correct_query in src/main.rs:1273) before searching. |
| BM25 length / saturation | Bm25Params |
k1=1.2, b=0.75 |
Lower b for corpora with wildly varying section lengths; raise k1 to reward repeated terms more. |
| Field weight | title_weight |
2.0 |
How much a title hit beats a body hit. Lower it if chapter/section titles are hijacking results. |
| Query inversion (debug) | LUME_QUERY_INVERSION=1 |
off | Round-trips the query’s GTR-T5 vector back to text (invert_vector in src/inversion.rs:30) so you can inspect the embedding. Costs an extra embed plus invert request and does not affect ranking. |
A worked example of the inversion trick: if semantic search keeps missing, set LUME_QUERY_INVERSION=1 and read what your query embeds back to. If “how does the prisoner escape” inverts to something about gardens, your embedding isn’t anchored on “escape” — reword, or lean lexical with a lower alpha.
8. Case study: the retrieval bug that confused the agent
To understand how these primitives interact, consider a real query run during testing over the full text of The Count of Monte Cristo: “How does Edmond Dantès’s father die?”
On Lume’s initial run, the answering agent returned: “The provided passages do not contain information regarding how Edmond Dantès’s father died.”
However, the death is fully detailed in the corpus. We traced this failure to three compounding issues at the query and retrieval parameter boundary:
- Proper-noun bias. The query planner generated keyword queries like
"Dantès father death". In Chapter 26, the father is referred to as “the old man” or “the elder Dantès”, and his death is described without the word “death” (“died of starvation”). Meanwhile, the literal chapter title “Father and Son” and broad entity matches onDantèspulled retrieval toward passages about the father while alive, pushing the target scene out of the evidence window. - Hardcoded retrieval depth. The number of passages fed to the LLM (
n_feed) was hardcoded to 10. When the target passage was pushed down in rank by proper-noun bias, it was clipped before the model could evaluate it. - Context pressure. Local model calls ran without an explicit
num_ctx, so prompts containing multiple passages could be truncated by the model runtime.
The fix
We corrected the behavior by adjusting the boundaries of our primitives:
- Query diversification. We updated the planner (
plan_queriesinsrc/answer.rs:49) to generate multiple query angles: one targeting explicit entities, one using event synonyms (e.g."died of starvation grief"), and one using secondary characters or details. - Dynamic feedback depth. We scaled
n_feeddynamically based on requested candidates:candidates.clamp(10, 20)insrc/main.rs:1797. - Explicit context bounds. We set
"num_ctx": 16384explicitly inollama_chat(src/answer.rs:21) and widened snippet sizes to 180 words.
With these changes, the planner’s query "died of starvation grief" surfaced the death scene in the retrieval set. The agent could then judge the evidence sufficient and generate a cited answer.
How the pieces fit
For a single query, Lume executes:
- Tokenize & filter.
tokenize(src/bm25.rs:452) and strip stopwords from the query string usingfilter_query_stopwords(src/bm25.rs:98). - Stage 1 (prune). Perform a roaring-bitmap union of term posting lists, then check Gödel tag signatures using
test_tag_prime(src/fast_retrieval.rs:449). - Stage 2 (lexical). Compute field-aware BM25 scores via
calculate_bm25_term_score(src/bm25.rs:728) and apply coordination factor (src/bm25.rs:644) over survivors. - Semantic primitive. Fetch GTR-T5 local dense neighbor scores using
query_semantic_search(src/hybrid.rs:637). - Graph primitive. Walk the significance-weighted graph using
compute_skg_scores(src/graph_search.rs:154). - Blend. Merge signals with
blend_hybrid_scores(src/hybrid.rs:673) and return the candidates.
The result is a ranking pipeline where each component can be inspected, turned down, or disabled without rewriting the rest of the system.
Lume is built by Steve Harris and Kord Campbell. Source: github.com/DeepBlueDynamics/lume. Line numbers above are against the current tree and drift as code moves — grep the symbol names (Bm25Index::search, blend_hybrid_scores, compute_skg_scores, cooccurrence_relatedness, handle_search) if they’ve shifted.
// transmission ends